Cilium is an open-source CNI plugin that leverages eBPF (extended Berkeley Packet Filter) to enhance Kubernetes networking. Running custom programs in the Linux kernel, Cilium outpaces traditional CNIs like Flannel or Calico by offering advanced security, observability, and Layer 3-7 control—all without modifying your apps.
Transparent Encryption: Secures communication with IPsec or WireGuard.
Hubble Observability: Real-time network insights.
Cilium’s strengths make it a standout for microservices-heavy clusters.
What is Hubble?
Hubble is a fully distributed networking and security observability platform for cloud native workloads. It is built on top of Cilium and eBPF to enable deep visibility into the communication and behavior of services as well as the networking infrastructure in a completely transparent manner. Hubble helps teams understand service dependencies and communication maps, operational monitoring and alerting, application monitoring, and security observability. [caption id="attachment_4990" align="alignnone" width="417"] Source: https://github.com/cilium/hubble/blob/main/Documentation/images/hubble_arch.png[/caption]
Why Cilium?
Traditional CNIs hit limits with scale—iptables slow down, and IP-based rules struggle with dynamic pods. Cilium’s eBPF approach and Layer 7 support, paired with Hubble’s visibility, address these gaps. But how does it compare to Istio? We’ll get there—first, a use case.
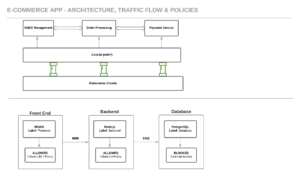
Use Case: Securing an E-Commerce Microservices App
Imagine managing a Kubernetes cluster for an e-commerce platform with user management, order processing, and payment services implemented using 3 tier web architecture:
Frontend: NGINX web server for customer requests.
Backend: Node.js API for user management, order processing & payment services.
Database: PostgreSQL for persisting sensitive data.
Requirements
Secure communication between microservices, ensuring that only authorized services can communicate with each other
Granular control over HTTP traffic, allowing specific endpoints to be exposed or blocked
Restrict frontend-to-backend traffic to port 8080.
Limit backend-to-database traffic to port 5432.
Block external database access.
Real-time visibility into network traffic for troubleshooting and security monitoring.
Cilium handles this with ease.
Use Case Diagram
Arrows (----->): Allowed traffic paths with ports.
Labels: Used for Cilium’s identity-based policies.
Blocked: External access denied by default.
Installing Cilium
Let’s install Cilium on your Kubernetes cluster. This section walks through prerequisites, setup, and validation for a smooth deployment.
Prerequisites
Kubernetes Cluster: Running 1.30+ (e.g., Minikube, Kind, or a cloud provider like EKS/GKE).
Helm: Version 3.x installed (helm version to check).
kubectl: Configured to access your cluster.
Linux Kernel: 4.9+ with eBPF support (most modern distros qualify—check with uname -r).
Step 1: Prepare Your Cluster
Ensure your cluster is ready:
kubectl get nodes
Step 2: Add Cilium Helm Repository Add and update the Helm repo:
Cilium transforms Kubernetes networking with eBPF, offering a potent mix of security, speed, and insight. Its installation is straightforward, and it shines in use cases like ours—while holding its own against Istio. Try it out and reach Keyva for any professional services support! [table id=13 /]
[post_title] => Cilium CNI & Hubble: A Deep Dive with Installation, Configuration, Use Case Scenario and Istio Comparison
[post_excerpt] =>
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => cilium-cni-hubble-a-deep-dive-with-installation-configuration-use-case-scenario-and-istio-comparison
[to_ping] =>
[pinged] =>
[post_modified] => 2025-05-21 16:55:42
[post_modified_gmt] => 2025-05-21 16:55:42
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://keyvatech.com/?p=4985
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
) [1] => WP_Post Object
(
[ID] => 5039
[post_author] => 7
[post_date] => 2025-05-05 19:50:28
[post_date_gmt] => 2025-05-05 19:50:28
[post_content] =>
Manage Your Entire IT Infrastructure with One Service Model.
Download now.
[post_title] => Create Seamless Integrations to Support Single Pane-of-glass Visibility
[post_excerpt] =>
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => create-seamless-integrations-to-support-single-pane-of-glass-visibility
[to_ping] =>
[pinged] =>
[post_modified] => 2025-05-05 19:50:28
[post_modified_gmt] => 2025-05-05 19:50:28
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://keyvatech.com/?p=5039
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
) [2] => WP_Post Object
(
[ID] => 4981
[post_author] => 7
[post_date] => 2025-04-29 15:07:41
[post_date_gmt] => 2025-04-29 15:07:41
[post_content] => Many things are usually easy when you first start out. For example, purchasing a new home is exciting and straightforward at first, but over time, maintenance issues arise, insurance costs and property taxes increase, and neighborhood dynamics change. Suddenly that dream home starts keeping you up at night. It is the same with the cloud.
Beyond the Cloud’s Silver Lining
Cloud adoption is easy at the beginning too. Cloud providers typically offer straightforward onboarding processes for small-scale migrations using an easy-to-use GUI interface. The pay-as-you-go model seems like a great deal compared to the cost of depreciating datacenter assets, forklift upgrades and software maintenance. Cloud offers a perfect alternative to fixed depreciating assets, especially when organizations have a need for increased workloads based on seasonal business trends. However, the more services and applications you migrate to the cloud, it becomes increasingly important to manage these assets in a standardized and streamlined manner.
Cloud costs can become increasingly difficult to manage as more services across multiple clouds are expanded, given that each cloud provider has a different pricing model, as well as costs can escalate rapidly due to factors like data transfer, storage, and unexpected usage spikes.
With increased cloud adoption, there is a tendency to overlook wasted resources. Once resources are provisioned manually, their continuous existence accrues on the monthly bill; so increased discipline is needed to keep the resource utilization to only what is needed.
Underutilization of resources is one of the biggest challenges in the Cloud. There is a tendency to overprovision the sizing of resources because they are available, and this causes wasteful spending for organizations.
In the beginning, cloud optimization may seem like a Day 2 exercise; however, it can quickly become an imperative activity if budgets are exceeded due to unintentional wastage of resources. The cloud is no different than on prem in the fact that it requires planning, continuous monitoring, and proactive management to ensure that everything runs to meet business objectives. It is something you cannot afford to put off.
Why aren’t Companies Achieving Cost Optimization?
If the cloud was supposed to be simpler than on-prem, then why does cloud optimization seem elusive to some organizations? A primary reason is the pace at which cloud transformation has taken place; the priority has often been “move to the cloud first and worry about optimization later”. It is an easy trap to get into. At Keyva, we've seen companies spend substantial amounts on cloud migrations, sometimes up to a million dollars per month. Imagine if you could save just 2% of that expenditure. That translates into real savings that could be reinvested in other business initiatives. Another reason why optimization isn’t achieved for a while is that like anything, the cloud has a learning curve, and some of those lessons can prove quite costly. Consulting with third-party experts who understand common pitfalls and mistakes can help you bypass the trial-and-error phase. These experts can guide you through the optimization process, ensuring you avoid the typical gotchas and costly errors and achieve cost efficiency and ROI sooner.
Achieving Operational Hygiene
We often hear about security hygiene. At Keyva, we also emphasize operational hygiene. That topic includes a lot of things, and one of the big ones is right-sizing. Overprovisioning is the #1 culprit of cloud overspending and it’s surprisingly easy to do. When choosing options in the cloud menu, the largest ones may be chosen for you by default, or you may be driven by normal human tendency to select a larger option. An organization should have guardrails to ensure a structured process for choosing the right amount and right-sized resource bundles. This can be done in several ways – by establishing a committee that must approve larger or expensive options to prevent unnecessary expenditures, or by using infrastructure as code methodologies. By incorporating chargeback and showback features which enhance cost visibility and accountability, it can be helpful to see the breakdown for features and resources used by various teams within the organization. Here’s how they work:
Showback provides detailed reports on cloud resource usage and associated costs without directly billing departments. It can serve as an educational tool to enhance cost awareness and help teams understand their cloud spending patterns and identify areas for cost optimization.
Chargeback involves directly billing departments or teams for their cloud resource usage to make them transparent. Tying costs to actual usage prevents wasteful spending and aligns cloud costs with departmental budgets. This approach promotes financial accountability and encourages teams to optimize their resource allocation.
Some Steps are Easy
Cloud optimization doesn't have to be complicated. It can be as simple as turning off resources after use. Just as you learned to turn off lights when leaving a room to save on the electric bill, you should deprovision resources when they're not needed. The sooner guardrails are set up to manage cloud costs, the better it is for adoption. While provisioning cloud native VMs or services in response to demand spikes is typically prioritized, turning them off after intended use or reducing the size and scale of utilized clusters should receive equal attention. All of this can be automated using infrastructure as code pipelines as well. License bundling is another simple but effective strategy for optimizing cloud costs as it helps streamline expenses, enhances flexibility and reduces administrative overhead. Much like cloud computing, where shared resources maximize efficiency, bundled licensing prevents service redundancies and minimizes underutilized cloud instances. By consolidating licenses, organizations ensure they are only paying for what they actually need, leading to greater cost efficiency and a more optimized cloud environment.
The 15-point Approach
At Keyva, we've developed a comprehensive 15-point strategy to achieve cloud optimization. When working with clients, we utilize monitoring to analyze key metrics such as average utilization, volume requests, and peak time utilization. This helps determine the optimal sourcing of resources. Monitoring is only valuable if it leads to actionable insights. At Keyva, we work with all the major cloud vendors, and use Well Architected Framework (WAF) model as a guide to achieving efficiency in systems and capacity. Our certified staff has worked with all major hyperscalers and cloud providers, and implemented WAF framework for multiple clients across various industry verticals. Cloud optimization is about finding real savings that can show an ROI quickly. Find out more about our 15-point strategy by contacting us today. [table id=3 /]
[post_title] => Cloud Optimization: Act Now or Pay Later
[post_excerpt] =>
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => cloud-optimization-act-now-or-pay-later
[to_ping] =>
[pinged] =>
[post_modified] => 2025-05-05 19:59:54
[post_modified_gmt] => 2025-05-05 19:59:54
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://keyvatech.com/?p=4981
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
) [3] => WP_Post Object
(
[ID] => 5185
[post_author] => 13
[post_date] => 2025-04-25 21:23:46
[post_date_gmt] => 2025-04-25 21:23:46
[post_content] =>
https://youtu.be/BQAbQNb-sOM
Keyva CTO Anuj Tuli discusses our expertise in infrastructure automation, security posture improvement, GitOps, and software integrations.
[post_title] => CTO Talks: Automation
[post_excerpt] =>
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => cto-talks-seamless-data-pump
[to_ping] =>
[pinged] =>
[post_modified] => 2025-12-15 22:31:47
[post_modified_gmt] => 2025-12-15 22:31:47
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://keyvatech.com/?p=5185
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
) [4] => WP_Post Object
(
[ID] => 4978
[post_author] => 15
[post_date] => 2025-04-17 14:53:36
[post_date_gmt] => 2025-04-17 14:53:36
[post_content] => At Evolving Solutions and Keyva, our Kubernetes expertise extends past the platform to your broader IT and business needs. While Kubernetes outperforms traditional virtual machine environments in flexibility and efficiency, its complexity can be daunting.
[post_title] => From Warm-Up Act to Headliner: The Rise of Kubernetes
[post_excerpt] =>
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => from-warm-up-act-to-headliner-the-rise-of-kubernetes
[to_ping] =>
[pinged] =>
[post_modified] => 2025-04-17 14:53:36
[post_modified_gmt] => 2025-04-17 14:53:36
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://keyvatech.com/?p=4978
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
) [5] => WP_Post Object
(
[ID] => 4974
[post_author] => 7
[post_date] => 2025-04-17 14:38:48
[post_date_gmt] => 2025-04-17 14:38:48
[post_content] => Read about a client faced an urgent issue when key IT personnel left the organization without leaving documentation artifacts. Download now [post_title] => Case Study: LAMP Stack Deployment Support
[post_excerpt] =>
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => case-study-lamp-stack-deployment-support
[to_ping] =>
[pinged] =>
[post_modified] => 2025-04-21 15:52:14
[post_modified_gmt] => 2025-04-21 15:52:14
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://keyvatech.com/?p=4974
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
) [6] => WP_Post Object
(
[ID] => 4873
[post_author] => 15
[post_date] => 2025-04-15 20:21:54
[post_date_gmt] => 2025-04-15 20:21:54
[post_content] =>
Comparing Bitfield/Scripts and Risor as alternatives to shell scripts
I don't like writing shell scripts. I like uniformity and predictability, easy to grok interfaces, and, if I can get it, type-hinting. And shell scripts have none of that, often written quick with little deference to the system they're participating in or the future maintainer. So it's unfortunate to me that shell scripts are the glue of automation, connecting disparate components and data across Linux to form pipelines. It's equally unfortunate is that, like glue, shell scripts are not always applied with care. When I came across Risor and "script" (github.com/bitfield/scripts), two projects with the goal of making script writing easier in Go, I had a lot of questions. How easy was it to write a script from scratch? What features are available? How easy was it to share scripts across hosts and pipelines? Could these really replace shell scripts? To answer those questions, I wanted to run a few tests to see how well each could perform and determine if either could perform as well as a regular shell script, and whether the drawbacks outweighed the benefits. I had 4 criteria I wanted to evaluate with each:
Getting started:
How difficult was it to install the tool or library and start executing a script?
Performance:
How well does the tool or library perform compared to standard shell scripts?
Distribution:
How difficult is it to share and execute scripts in different environments?
Maintenance:
How difficult is it to learn the tool or library to contribute or troubleshoot?
Weighing those together, not in any scientific or numerical scale, will at least give an idea of how these projects compare to each other, how they could potentially replace bash in existing workflows, and when they might be worth considering.
Risor
Risor is a CLI tool and Go package that reads and executes files written in Risor's DSL.
Installing and Getting Started with Risor
There are two ways of using Risor: As an executable and as a package. Installing the executable is simple for Mac users: Risor has a package available through Homebrew (brew install risor) that handles installing the tool and any dependencies. On other platforms, there isn't a precompiled binary (that I could find in the docs), so the tool needs to be built before it can be used. That means installing Go and configuring the environment, cloning the project, and running the go install. Not especially difficult, but more work than required for MacOS. Using the Risor package is the same process on all platforms, requiring Go's build tools, and is pulled down to the environment in the same method as any other Go package.
Risor modules
Functionality within Risor is implemented by compiling and installing various modules along with the project and then exposing as the DSL at the script later. Modules are included for interacting with the OS, DNS, JSON, and other tools and applications like Kubernetes. While there are many cases where the DSL doesn't really provide a benefit, like reading files or printing text where shell languages are already simple enough, the more advanced and specific modules provide a much simpler interface. For example, the tablewriter module can take arrays of data and print nice looking tables to the shell. I can see uses where I'm trying to display a table of data during a pipeline and implementing it in Risor is much easier than in other languages. Risor also has documentation for implementing custom modules and contributing them back to the project or distributing them privately.
Creating an example Risor script
For the first test, I created a temporary directory to start from and installed Risor.
$ cd $(mktemp -d)
$ brew install risor
Second, I created a script read_file to read a file and print the contents to stdout.
To generate the comparison, I started a timer and loop and executed each script 1000 times to get a little easier number to compare.
# Shell script
$ time zsh -c 'for i in {1..1000}; do ( ./shell_script ./test.txt >> /dev/null ); done'
zsh -c 0.02s user 0.15s system 3% cpu 4.420 total
# Risor
$ time zsh -c 'for i in {1..1000}; do ( ./read_file ./test.txt >> /dev/null ); done'
zsh -c 'for i in {1..1000}; do ( ./read_file ./test.txt >> /dev/null ); done' 0.04s user 0.20s system 1% cpu 18.706 total
Performing the file read 1000 times with Risor took 18.7 seconds. Performing that same operation with just Zsh took only 4.4 seconds. Side note: Assigning the argument to a variable in the shell script slowed it down by almost half (47%), whereas assigning the argument to a variable in Risor made almost no different (2%). Is it enough to be noticeable? Probably. Considering that this is a very small example, reading and printing a file, performed a thousand times, the difference of an individual run is milliseconds, and in isolation, may never be noticed. But, for more complex scripts reading multiple files and performing string transforms, or multiple scripts run at different points in a pipeline, those delays start adding up.
Distributing Risor scripts
Risor executes these scripts when executed by reading the script file, parsing the DSL, and executing it. There are a few available methods for distributing and executing Risor scripts across hosts:
Install Risor and custom modules anywhere the scripts will need to run, following the normal installation steps,
Create and build a Go project that utilizes the Risor package and distribute those binaries from a repository,
Or compile the scripts using another a separate tool, like com/rubiojr/rsx, and distribute the binaries.
Compared to sharing shell scripts, none of these solutions are particularly simple. All require the installation of outside tools or complicated methods of packaging. I had really hoped there would be a way to compile scripts using the same toolset that is used to execute them, but it's either not possible or not yet implemented.
Bitfield/Scripts
script is a Go package that exposes shell executables and functionality as Go-like objects.
Getting started with script
Since script is a Go package, installing and getting started doesn't require applications outside of the Go toolset, and is identical for each platform
Install and configure Go environment
Create a new module for code go mod init go.example.com/script
Fetch and add dependency go get github.com/bitfield/script
While altogether not difficult, I've always lamented Go's requirement that everything be a module. It's difficult to work quickly to prototype a solution because of the requirement to initiate a module, define dependencies, etc., when all I want to do is test if my code works. For me, the benefits of using script get lost quickly because it doesn't provide anything that couldn't be gained by just writing in Shell or Python. Because scripts must be compiled by script before they can be run, leaving go run ... aside because that still requires the entire environment, the quick nature of writing them is lost and writing them is similar to any other Go-compiled executable.
Creating a script test
I implemented the same functionality in the script example that I did for Risor, so I started by creating a new temp directory and a new module.
$ cd $(mktemp -d)
$ go mod init go.example.com/script
go: creating new go.mod: module go.example.com/script
Then I add the script dependency and created the new script.
Not too bad, either. There's much more code involved, and it admittedly took a bit of debugging to figure out .String() would always append a newline and there wasn't a way to access arguments individually, but once figured out it was simple to get going.
script performance vs. shell
Since my script is a compiled Go executable, I hoped that the performance would be improved, as well. To test, I performed the same test as Risor and ran the script through a loop 1000 times to get a bigger number to compare between the two.
# Shell script results (from earlier)
$ time zsh -c 'for i in {1..1000}; do ( ./shell_script ./test.txt >> /dev/null ); done'
zsh -c 0.02s user 0.15s system 3% cpu 4.420 total
$ time zsh -c 'for i in {1..1000}; do ( ./read_file ./test.txt >> /dev/null ); done'
zsh -c 'for i in {1..1000}; do ( ./read_file ./test.txt >> /dev/null ); done' 0.02s user 0.15s system 4% cpu 3.800 total
script completed 1000 iterations in 3.8 seconds, beating the Zsh script by 16%! In my previous experience, Go executables have rarely outperformed pure shell scripts. Will it make a noticeable different in execution time in real-world use? I doubt it. It's a difference of half a second across a thousand operations. But, it being close means performance is not a reason to avoid using script.
Distributing script executables
script projects produce executable binaries, similar to the binaries produced by any Go project. So, an executable produced by script will be able to run on similar hosts without needing to install additional dependencies. This is familiar for Go projects, and one of the main benefits of Go. That does come with it’s own challenges, though. Go builds binaries for a target CPU architecture, unless given a target architecture to build. So, when distributing a script, the build pipeline will need to build and push a version for each target architecture. The other option left is to generate the binary on the host that will run it. Doing that loses out on one of the major benefits of Go, requiring the Go toolset be installed and configured everywhere it will be run. Building a project for multiple architectures is a familiar requirement for Go development, so it's not inherently a negative.
script interpreter
I like that the scripts can be compiled, but I wished there was a way to execute the script without needing to compile it. Being able to view the source and execute it, without other dependencies, is something that Shell scripts do well, and can speed up debugging broken pipelines. Within the script documentation, it provides an example script to run script projects using just the provided code. This script will take the provided source, generate a temporary Go project, and compile and execute the script. I can see some issues with that right away, but I created a goscript.sh within the same project to test it. I'll save pasting the full goscript.sh here, but it can be found in the original post linked by the documentation. I created a .goscript file using the using the code from the main.go.
So, immediately, there's a problem. Without altering the goscript.sh, the interpreter script doesn't include any package dependencies, meaning it's limited to only the functionality exposed by the github.com/bitfield/script package or built-in to Go. It's an interesting project, but the limitations are too imposing: The full Go toolset needs to be installed, and the script can only use the script package and API.
Comparing the tools
In the beginning, I laid out 4 criteria I was going to use to assess these projects:
Getting started
Performance
Distribution
Maintenance
Risor vs. script
First, I'll compare the two projects to each other, and then compare the "winner" to just using Shell languages.
1. Getting started
Under the "Getting Started" criteria, I give it to Risor. Risor provided me with an easier starting process. No project needed to be created and installing the tool was a single command (thanks to Homebrew). script was a bit more involved, requiring everything needed of a Go project, including Go source, regardless of platform it was developed on. Risor 1, script 0.
2. Performance
"Performance"-wise, the clear winner is script. script was over 400% faster than Risor, and was able to perform simple operations more efficiently than the same test in Risor. Risor 1, script 1.
3. Distribution
I give the "Distributing" category again to `script`. Risor is more flexible, allowing scripts to be interpreted and run on any platform that the Risor executable is installed on. But, those Risor scripts will always require installing external dependencies to run. Compiling for multiple architectures may be more work, but `script` projects can be installed and run as a single file, so sharing them amongst platforms doesn't require vetting additional dependencies to install. Risor 1, script 2.
4. Maintenance
For long-term maintenance, I give the point to script. Both projects require some knowledge of the API, Risor using a custom DSL and script using Go structs, interfaces, and functions. But, like introducing a new language to an environment, adopting a DSL should always be a conscious, deliberate choice. It takes time for a developer to learn an API and a project, and adding a DSL eliminates the benefit of knowing that language. script also can be deployed to hosts without outside dependencies, so there are no additional packages to keep updated. Risor 1, script 3.
Better than shell?
After weighing all that, the question is, "is script better than writing shell scripts"? In my non-scientific, completely arbitrary position: Not particularly. I can see specific use cases where I will use script in the future. In places where maybe I would put a shell script to perform structured operations, like querying known sources and generating JSON for pipeline inputs, I may look at script as an alternative. But, that assumes that I know ahead of time that the team I'm working with can take it over. If the maintainers don't know Go, then I might as well hand them a jigsaw puzzle. Shell languages being so ubiquitous means that it's likely most developers have enough knowledge to trouble shoot the issues, without needing to learn an entire other language and toolset. And what’s provided by using script needs to be compelling enough to give up that simplicity. The performance of script was surprising, though, and I am excited to implement script for personal projects. I'd held off from writing those personal projects in Go because the startup times were painful and it didn't provide enough of a benefit to rewrite them. But I'm eager to see if I can gain the distribution improvements and only have to download a single file rather than a whole library. If you would like to learn more or have a conversation about go-based scripting, contact us. [table id=12 /]
[post_title] => Testing Different Go-based Scripting Projects
[post_excerpt] =>
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => testing-different-go-based-scripting-projects
[to_ping] =>
[pinged] =>
[post_modified] => 2025-03-25 20:35:56
[post_modified_gmt] => 2025-03-25 20:35:56
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://keyvatech.com/?p=4873
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
) [7] => WP_Post Object
(
[ID] => 4916
[post_author] => 15
[post_date] => 2025-04-02 20:35:04
[post_date_gmt] => 2025-04-02 20:35:04
[post_content] => Improving efficiency and productivity remains a core business imperative. As management expert Peter Drucker noted, 'Efficiency is doing better what is already being done.' It is in the pursuit of that endeavor that companies continually strive to enhance efficiency throughout their operations, seeking improvements in areas such as labor, logistics, supply chains, and resource management In today's digital age, there's another critical area where businesses can extract greater efficiencies: data transfer and synchronization. In the past, industries like healthcare, finance, and retail were the primary data-driven sectors. Today, you would be hard pressed to find any business that doesn’t rely on real-time data.
Data Latency, the Silent Productivity Killer
Latency is the nemesis of network administrators, negatively impacting application performance and user experiences. However, there is another form of latency that can prove just as detrimental: data latency. Data latency hampers timely decision-making, resulting in missed opportunities and suboptimal resource allocation. Business success hinges on delivering data to decision-makers at the velocity required for meaningful action. Not long ago, companies relied on monthly statements to monitor their accounts, constraining many critical decisions to a monthly cycle. Today, credit card holders receive instant notifications of their transactions in real-time, exemplifying the power of immediate data flow. Without real-time data, financial statements may be outdated or incorrect, leading to poor financial decision making. The flow of real time data accelerates decision making. The faster that your company can make decisions, the faster it can capitalize on emerging opportunities and maintain a competitive edge. Speed, however, is only part of the equation. Data quality is equally crucial. According to a 2021 Gartner study, poor data quality costs organizations an average of $12.9 million a year. The combination of delayed data flow and poor data quality creates significant business risks. These risks come in the form of higher operational costs rising as employees waste time manually gathering and validating information. Customer satisfaction suffers when inaccurate or delayed data leads to poor service and inconsistent communication, eroding trust. Supply chains falter when outdated data drives inventory and logistics decisions, resulting in stockouts, overstock, and delivery failures. Security weakens as inefficient data handling leaves sensitive information vulnerable to breaches. IT teams struggle under the burden of manual workarounds and troubleshooting, driving up costs while reducing efficiency.
A Magic Fountain
What if there were a magical fountain that could significantly increase data transfer and synchronization overnight? One that took care of everything behind the scenes, transforming your data management processes with nearly no effort on your part so that data flowed fluidly and unabated across your organization? This hypothetical "fountain" could transform your data operations by:
Creating automatic mappings between disparate data sources
Consolidating data from all external sources into a single source of truth
Performing real-time data synchronization across systems
Applying data quality checks and cleansing procedures
Managing data security and encryption during transfers
Providing detailed logging and auditing of all data movements
Offering intelligent scheduling to minimize impact on system performance
The good news is that this hypothetical fountain comes in the form of the Keyva Seamless Data Pump. This data integration platform efficiently transfers large datasets between on-premises and cloud systems while securing and transforming data to match each end user's required format.
Set It and Forget It
Once configured, the Data Pump operates with minimal intervention. It can be set up to be functional in under 45 minutes. That is possible because it comes with preconfigured settings and built-in maps to get you started quickly. By transforming data integration into a set of repeatable, automated processes, it eliminates the need for tedious manual data entry of traditional Extract, Transform, Load (ETL) processes that:
Lack flexibility
Require continuous maintenance
Typically has high setup costs.
The Data Pump has an internal scheduler that allows you to automate data synchronization at off-peak hours to reduce network load and ensure consistent updates without manual oversight. This puts you in charge of when this automation occurs. Thanks to its emphasis on security, you can also forget worrying about compliance issues with your data transfers because the Data Pump ensures end-to-end encryption, access controls, and audit logging to meet operational requirements.
Reaping the Rewards of Efficient Data Transfer
Still wondering how a more efficient data transfer management platform can benefit your business. Let's explore three industry examples to illustrate:
A major hospital reduces administrative errors and patient wait times by streamlining data flow between departments that use a common CMDB or a common data model. This improvement enables doctors to make faster, better-informed decisions, ultimately leading to superior patient outcomes.
A national retailer implements automated data transfer to monitor inventory levels in real-time across thousands of stores. This visibility eliminates costly stockouts and overstock situations, optimizing their supply chain.
A credit card company accelerates data analysis to better understand customer spending patterns. With faster access to insights, they create personalized rewards and targeted campaigns that increase both customer engagement and card usage.
Keyva
At Keyva, we understand that efficient, secure data flow is the lifeblood of modern business. We also know that you don’t have the resources to reinvent the wheel, which is why our solutions are designed to transform using your existing assets and best-of-breed hybrid solutions. The Keyva Seamless Data Pump exemplifies our commitment to transforming client operations through innovative automation. Our team can assess your environment, identify inefficiencies, and implement a solution that optimizes your data transfer processes. This creates tangible and measurable value for your organization and customers. Whether you need a hands-off solution or a tailored approach for your unique enterprise requirements, we ensure your data flows seamlessly and securely at the necessary velocity to drive business success. [table id=9 /]
[post_title] => The Data Velocity Advantage: Boosting Transfer and Sync Efficiency
[post_excerpt] =>
[post_status] => publish
[comment_status] => closed
[ping_status] => closed
[post_password] =>
[post_name] => the-data-velocity-advantage-boosting-transfer-and-sync-efficiency
[to_ping] =>
[pinged] =>
[post_modified] => 2025-03-25 20:35:22
[post_modified_gmt] => 2025-03-25 20:35:22
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://keyvatech.com/?p=4916
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
) ) [post_count] => 8
[current_post] => -1
[before_loop] => 1
[in_the_loop] =>
[post] => WP_Post Object
(
[ID] => 4985
[post_author] => 15
[post_date] => 2025-05-14 16:22:39
[post_date_gmt] => 2025-05-14 16:22:39
[post_content] => Kubernetes powers modern cloud-native infrastructure, but its networking layer often demands more than basic tools can deliver—enter Cilium, an eBPF-powered Container Network Interface (CNI). This blog explores Cilium’s features, a practical use case with a diagram, step-by-step installation and configuration, and a comparison with Istio. Whether you’re securing workloads or optimizing performance, Cilium’s got something to offer—let’s dive in!
What is Cilium CNI?
Cilium is an open-source CNI plugin that leverages eBPF (extended Berkeley Packet Filter) to enhance Kubernetes networking. Running custom programs in the Linux kernel, Cilium outpaces traditional CNIs like Flannel or Calico by offering advanced security, observability, and Layer 3-7 control—all without modifying your apps.
Transparent Encryption: Secures communication with IPsec or WireGuard.
Hubble Observability: Real-time network insights.
Cilium’s strengths make it a standout for microservices-heavy clusters.
What is Hubble?
Hubble is a fully distributed networking and security observability platform for cloud native workloads. It is built on top of Cilium and eBPF to enable deep visibility into the communication and behavior of services as well as the networking infrastructure in a completely transparent manner. Hubble helps teams understand service dependencies and communication maps, operational monitoring and alerting, application monitoring, and security observability. [caption id="attachment_4990" align="alignnone" width="417"] Source: https://github.com/cilium/hubble/blob/main/Documentation/images/hubble_arch.png[/caption]
Why Cilium?
Traditional CNIs hit limits with scale—iptables slow down, and IP-based rules struggle with dynamic pods. Cilium’s eBPF approach and Layer 7 support, paired with Hubble’s visibility, address these gaps. But how does it compare to Istio? We’ll get there—first, a use case.
Use Case: Securing an E-Commerce Microservices App
Imagine managing a Kubernetes cluster for an e-commerce platform with user management, order processing, and payment services implemented using 3 tier web architecture:
Frontend: NGINX web server for customer requests.
Backend: Node.js API for user management, order processing & payment services.
Database: PostgreSQL for persisting sensitive data.
Requirements
Secure communication between microservices, ensuring that only authorized services can communicate with each other
Granular control over HTTP traffic, allowing specific endpoints to be exposed or blocked
Restrict frontend-to-backend traffic to port 8080.
Limit backend-to-database traffic to port 5432.
Block external database access.
Real-time visibility into network traffic for troubleshooting and security monitoring.
Cilium handles this with ease.
Use Case Diagram
Arrows (----->): Allowed traffic paths with ports.
Labels: Used for Cilium’s identity-based policies.
Blocked: External access denied by default.
Installing Cilium
Let’s install Cilium on your Kubernetes cluster. This section walks through prerequisites, setup, and validation for a smooth deployment.
Prerequisites
Kubernetes Cluster: Running 1.30+ (e.g., Minikube, Kind, or a cloud provider like EKS/GKE).
Helm: Version 3.x installed (helm version to check).
kubectl: Configured to access your cluster.
Linux Kernel: 4.9+ with eBPF support (most modern distros qualify—check with uname -r).
Step 1: Prepare Your Cluster
Ensure your cluster is ready:
kubectl get nodes
Step 2: Add Cilium Helm Repository Add and update the Helm repo:
Kubernetes powers modern cloud-native infrastructure, but its networking layer often demands more than basic tools can deliver—enter Cilium, an eBPF-powered Container Network Interface (CNI). This blog explores Cilium’s features, a ...
Many things are usually easy when you first start out. For example, purchasing a new home is exciting and straightforward at first, but over time, maintenance issues arise, insurance costs ...
At Evolving Solutions and Keyva, our Kubernetes expertise extends past the platform to your broader IT and business needs. While Kubernetes outperforms traditional virtual machine environments in flexibility and efficiency, its complexity can ...
Comparing Bitfield/Scripts and Risor as alternatives to shell scripts I don’t like writing shell scripts. I like uniformity and predictability, easy to grok interfaces, and, if I can get it, ...
Improving efficiency and productivity remains a core business imperative. As management expert Peter Drucker noted, ‘Efficiency is doing better what is already being done.’ It is in the pursuit of ...
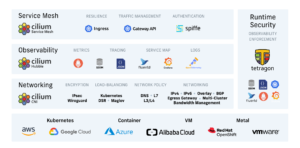
 Source: https://github.com/cilium/cilium/blob/main/Documentation/images/cilium-overview.png[/caption]
Source: https://github.com/cilium/cilium/blob/main/Documentation/images/cilium-overview.png[/caption] 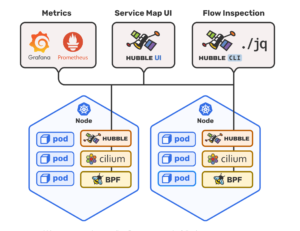
 Source: https://github.com/cilium/hubble/blob/main/Documentation/images/hubble_arch.png[/caption]
Source: https://github.com/cilium/hubble/blob/main/Documentation/images/hubble_arch.png[/caption]