Get Appointment
- contact@wellinor.com
- +(123)-456-7890
Blog & Insights
- Home
- Blog & Insights
By: Saikrishna Madupu – Sr Devops Engineer
In this blog, we will cover what is Goss, and how to leverage it for automated server validation testing.
What is Goss:
Goss is a YAML based serverspec alternative tool for validating a server’s configuration. It eases the process of writing tests by allowing the user to generate tests from the current system state. Once the test suite is written they can be executed, waited-on, or served as a health endpoint. You can do server validation quickly and easily with Goss and integrate with pipelines to monitor the status of any services.
I’ll be using airflow for a target test case. First, we will install airflow locally and validate the status of airflow service status using Goss.
https://github.com/aelsabbahy/goss
Goss Installation:
- OPTION 1:
curl -L https://github.com/aelsabbahy/goss/releases/download/v0.3.7/goss-linux-amd64 -o /usr/local/bin/goss
curl -L https://raw.githubusercontent.com/aelsabbahy/goss/master/extras/dgoss/dgoss -o /usr/local/bin/dgoss
chmod +rx /usr/local/bin/dgoss- OPTION 2:
https://ports.macports.org/port/goss/
Install Macports and run
sudo port install goss
## Add the following line to your ~/.profile or .zshrc
export GOSS_PATH=/usr/local/bin/goss
Use Case:
We will deploy Apache Airflow locally and validate the status of webserver using Goss. Airflow is an open-source project used to programmatically author, schedule, and monitor workflows. You can find more about airflow here - https://airflow.apache.org/
export AIRFLOW_HOME=~/airflow
pip3 install apache-airflow
pip3 install typing_extensions
# initialize the database
airflow initdb
# start the web server, default port is 8080
airflow webserver -p 8080
# start the scheduler. I recommend opening up a separate terminal \
# window for this step
airflow scheduler
# open localhost:8080 in the browser and enable the example dag via the home page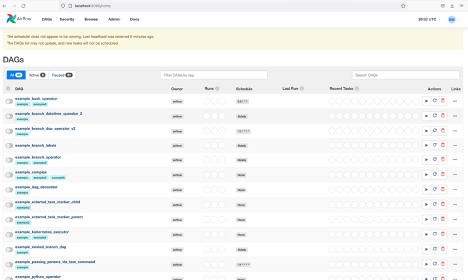
Validation:
Goss.yaml file validates HTTP response status code and content
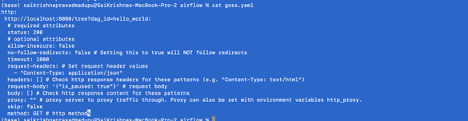
export GOSS_USE_ALPHA=1
goss validate goss.yaml

- As the webserver is not up and running we see the error above
After starting the airflow webserver and making sure the application is up and running by validating it (via opening the page in a browser)
- goss validate goss.yaml would return the status report as shown below.

- Goss also supports several other test cases. Some of those are listed below:
- Addr
- Command
- Dns
- Ount
- Package
- Service
Ref: https://github.com/aelsabbahy/goss/blob/master/docs/manual.md#goss-test-creation
About the Author
[table id =5 /]
[post_title] => GOSS Server Validation [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => goss-server-validation [to_ping] => [pinged] => [post_modified] => 2022-08-23 22:00:44 [post_modified_gmt] => 2022-08-23 22:00:44 [post_content_filtered] => [post_parent] => 0 [guid] => https://keyvatech.com/?p=3335 [menu_order] => 0 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [1] => WP_Post Object ( [ID] => 3302 [post_author] => 7 [post_date] => 2022-08-05 16:35:20 [post_date_gmt] => 2022-08-05 16:35:20 [post_content] =>Keyva is pleased to announce the certification of our ServiceNow App for Red Hat Ansible against the latest ServiceNow San Diego release. This release is the newest updated software version since the company's inception.
Customers can now seamlessly upgrade their ServiceNow App from previous ServiceNow releases (Quebec, Rome) to the San Diego release.
Learn more about the Keyva ServiceNow App for Ansible and view all the ServiceNow releases for which it has been certified at the ServiceNow store, visit https://bit.ly/ansible_servicenow.
[post_title] => ServiceNow App for Red Hat Ansible - Certified for San Diego Release [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => servicenow-app-for-red-hat-ansible-certified-for-san-diego-release-2 [to_ping] => [pinged] => [post_modified] => 2024-05-28 18:29:55 [post_modified_gmt] => 2024-05-28 18:29:55 [post_content_filtered] => [post_parent] => 0 [guid] => https://keyvatech.com/?p=3302 [menu_order] => 0 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [2] => WP_Post Object ( [ID] => 3282 [post_author] => 15 [post_date] => 2022-07-28 17:40:42 [post_date_gmt] => 2022-07-28 17:40:42 [post_content] =>In this blog we will be discuss best practices to handle Kubernetes security by implementing Kyverno policies. We’ll be using a KIND cluster to demonstrate our use cases.
What is Kyverno:
Kyverno is a policy engine (controller) which applies policies to Kubernetes resources. It helps to verify if deployments are adhering to defined standards, and to implement best practices by defining certain conditions (policies). It includes many features, and some of the benefits (not an exhaustive list) are listed below:
- Define policies as Kubernetes resources (no new language to learn!)
- Validate, mutate, or generate any resource
- Verify container images for software supply chain security
- Inspect image metadata
- Match resources using label selectors and wildcards
- Validate and mutate using overlays (like Kustomize!)
- Synchronize configurations across Namespaces
- Block non-conformant resources using admission controls, or report policy violations
- Test policies and validate resources using the Kyverno CLI, in your CI/CD pipeline, before applying to your cluster
- Manage policies as code using familiar tools like git and kustomize
How it Works:
Kyverno runs as an admission controller within the Kubernetes cluster. When Kyverno policies are applied to the cluster and someone tries to deploy any of the resources in that cluster, Kyverno receives the request, validates via mutating admission webhook HTTPS callbacks from the kube-apiserver, and applies matching polices to return results that enforce admission policies or reject requests.
Here is the overall workflow -
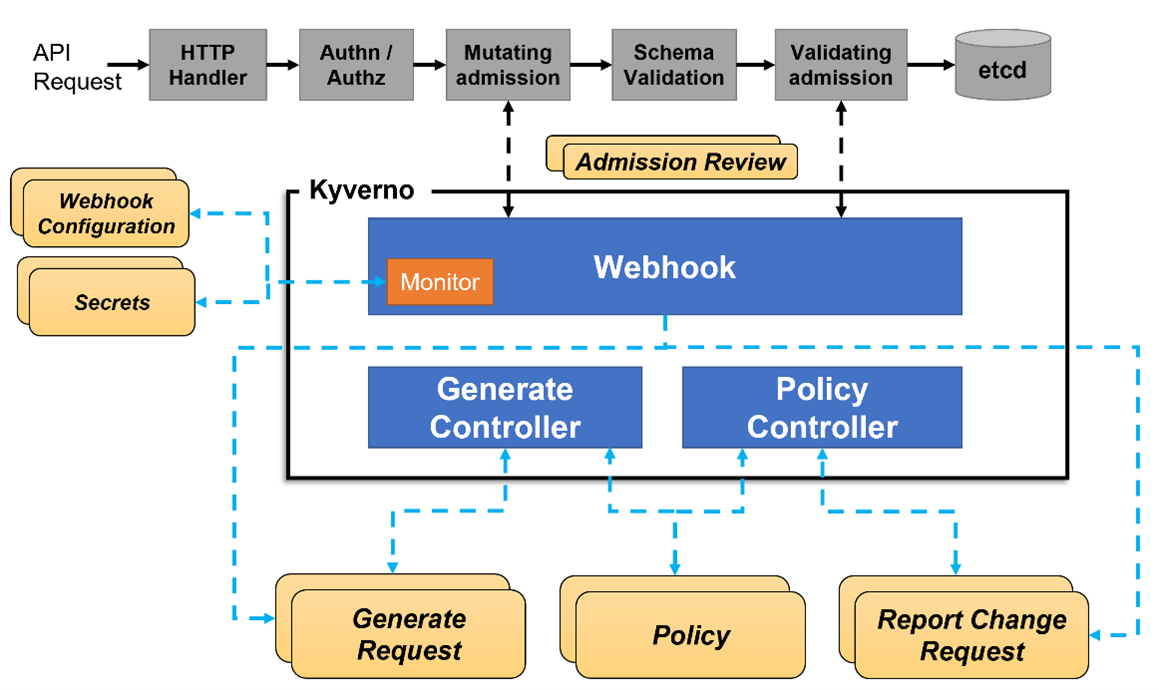
Installation: Kyverno can be installed using either helm or yaml file.
Option1:
kubectl create -f https://raw.githubusercontent.com/kyverno/kyverno/main/definitions/release/install.yaml
Option2:
helm repo add kyverno https://kyverno.github.io/kyverno/
helm repo update
helm install kyverno-policies kyverno/kyverno-policies -n kyverno
Use Cases:
We will walkthrough the following examples:
- Disallow the creation of pods in default namespaces
- Restricting the pods if they are not labeled during deployment
- Adding default labels as part of any resource that gets created
- Disallow the creation of pods in default namespaces
We will define restrict-default.yaml as below
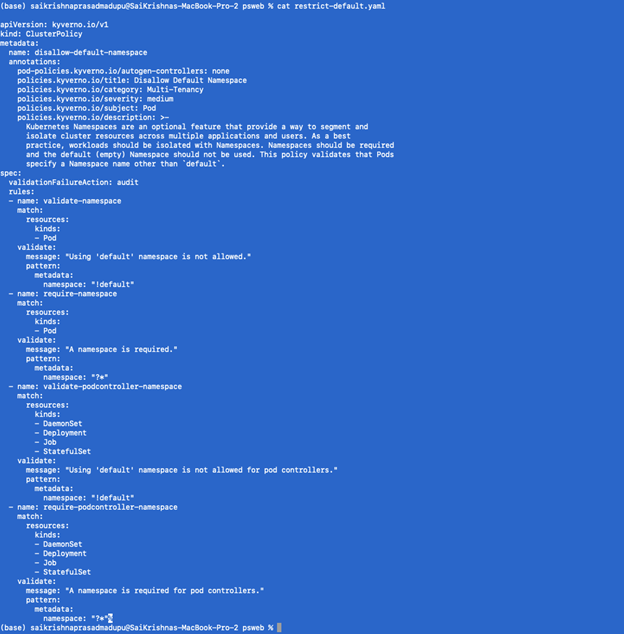
Next, we will apply this policy
Kubectl apply -f restrict-default.yaml
In the below screenshot you can see the steps on how to validate that the appropriate Kyverno policy was applied to the deployment.
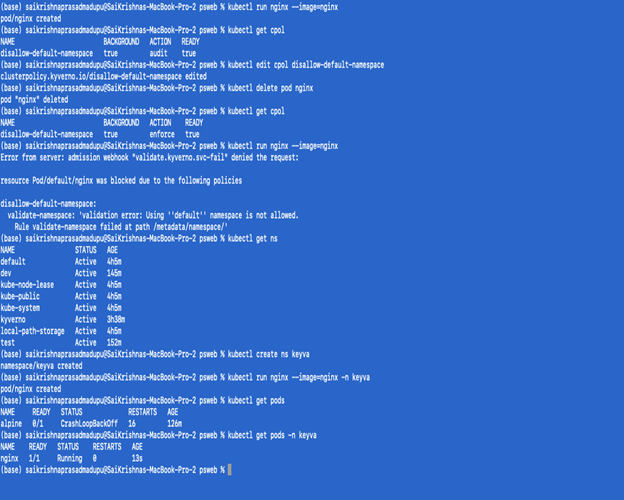
Note:
- If you notice the policy is not in an active state, try again with setting the action state to enforced.
- Deleting the policies:
- Kubectl delete cpol –all
- Ref: https://kyverno.io/docs/introduction/
- Restricting the pods if they are not labeled during deployment:
We will define require-labels.yaml as follows
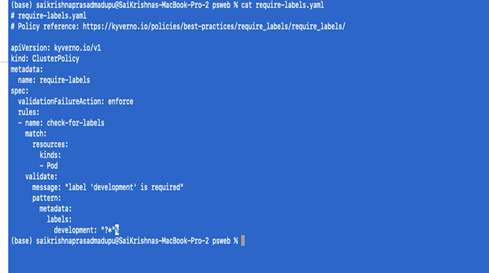
kubectl apply -f require-labels.yaml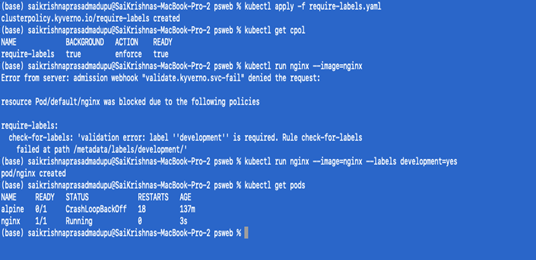
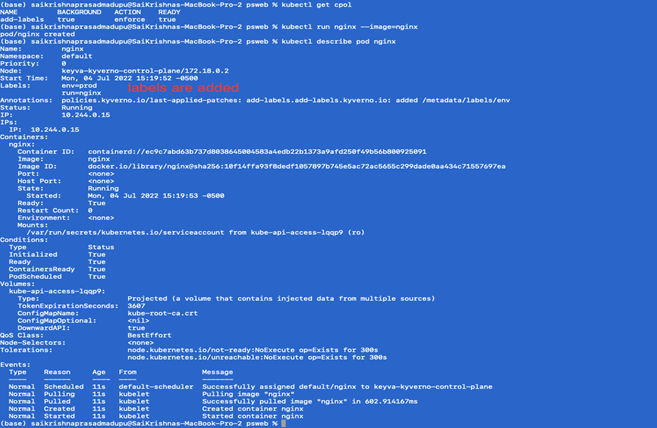
Adding default labels as part of any resource that gets created:
To configure a mutate policy of our KIND Cluster’s ClusterPolicy, and add labels such as env: prod on pods and other resources creation, create default-label.yaml as per below:
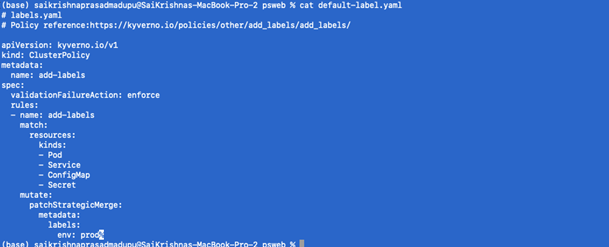
- Apply the policy
Kubectl apply -f default-label.yaml
Keyva is pleased to announce the certification of our ServiceNow App for the Red Hat OpenShift against San Diego release. This release is the newest updated software version since the company's inception.
Customers can now seamlessly upgrade their ServiceNow App for OpenShift from previous ServiceNow releases (Quebec, Rome) to the San Diego release.
Learn more about the Keyva ServiceNow App for Red Hat OpenShift and view all the ServiceNow releases for which it has been certified at the ServiceNow store, visit https://bit.ly/openshift_servicenow.
[post_title] => ServiceNow App for Red Hat OpenShift - Certified for San Diego Release [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => servicenow-app-for-red-hat-openshift-certified-for-san-diego-release [to_ping] => [pinged] => [post_modified] => 2024-05-28 18:21:35 [post_modified_gmt] => 2024-05-28 18:21:35 [post_content_filtered] => [post_parent] => 0 [guid] => https://keyvatech.com/?p=3273 [menu_order] => 0 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [4] => WP_Post Object ( [ID] => 3250 [post_author] => 15 [post_date] => 2022-06-27 19:07:00 [post_date_gmt] => 2022-06-27 19:07:00 [post_content] =>Red Hat Ansible and OpenShift are used by organizations worldwide as one of the top solutions for DevOps automation at scale. If your enterprise is managing thousands of endpoints or dealing with increasingly larger workloads, then there is a case to be made to implement Ansible with OpenShift as a solution that scales with your project workloads.
Here’s an overview of how Ansible and OpenShift can work together.
The Role of Ansible
RedHat Ansible is a configuration management tool available in open-source and enterprise versions. Using automated playbooks, DevOps teams can script out the configuration and setup of hardware and software under their responsibility.
Any enterprise seeking an automation solution for their infrastructure or application deployments is an ideal user for Ansible. It's one of the most popular open-source software solutions on the market right now, and a de facto solution for standardized configuration management. Such popularity brings with it an active open-source community of contributors who are developing free modules and collections – integrations to third-party products such as networking, storage, and SaaS platforms. Ansible has thousands of modules, collections, and roles available for free via Ansible Galaxy.
The open-source and enterprise versions of Ansible are easy to use. Developers and engineers can write Ansible playbooks using YAML, a simple markup language that doesn't require any formal programming background. The primary use cases for Ansible are infrastructure automation for on-premise and cloud systems, and configuration management. Ansible provides Platform and Operations teams a common and standardized tool to be used across different workload types.
The Value of Red Hat OpenShift
Red Hat OpenShift helps with the orchestration of containerized workloads. And these container workloads can be application services, databases, and other technology platform components.
Red Hat OpenShift is easy to set up and configure. The installation process leverages bootstrap mechanism to create installer-provisioned infrastructure. You can also use user-provisioned infrastructure to accommodate any customizations during install time. Additionally, you can use Ansible Playbooks and Roles to configure OpenShift, removing the need for human intervention.
Ansible and OpenShift play together throughout the workload deployment lifecycle. DevOps teams can use OpenShift’s console to manage and maintain their containerized workloads. Ansible automation plays an important part for configuration updates and helping integrate with CI/CD pipelines when releasing the application to lower and production environments. Automated security scanning validates the security of code throughout the development cycle. Ansible also provides an easy way to access third-party integrations such as SonarQube, a code checking engine, plus a range of other open-source and proprietary tools enabling you to test application workloads in a lower environment before deployment with OpenShift to a production environment.
Centralizing Infrastructure Automation at Scale
Most organizations benefit from using centralized infrastructure for OpenShift and Ansible. This way, they can scale across multiple teams, while allowing members from various teams to contribute towards these platforms, and towards automation goals at large. This also helps manage licensing costs by avoiding duplication targets, and most importantly, makes operational sense.
Now consider a scenario where an enterprise uses Puppet, Chef, or another open-source automation tool with or without Ansible. Their DevOps teams may have yet to set a standard automation tool leaving them dependent on an employee’s knowledge. Keyva has worked with several customers in this very situation, especially organizations that have aggressive acquisition strategies. By conducting several lunch-and-learn sessions, as well technical and business level briefings, we’ve helped organizations with tools consolidation as well as a charted path to reducing technical debt and risks associated with tools proliferation. We’ve also done client-specific assessments that analyze multiple automation platforms to determine the best fit for a client’s specific business and technology use cases.
Ansible and OpenShift: Better Together
Ansible, in conjunction with OpenShift, drives Infrastructure automation and operational excellence which goes hand in hand to work through the toughest of DevOps use cases. Keyva has extensive experience using a vendor-agnostic approach to building complete pipelines to meet a customer’s particular use case. We have experience working with Azure DevOps, GitHub, Jenkins, and many other pipeline tools from several past projects. Our approach is flexible and consultative. We don’t prescribe a one-size-fits-all framework to our customers who may be looking for solutions customized for their organization. The breadth of experience of our consulting team enables us to work on specific client needs, in whatever roles the client requires, within our skills portfolio.
Bringing together Ansible and OpenShift into an existing or new DevOps pipeline has the potential to move any enterprise to the next level of automation maturity. Ansible brings human operational knowledge in the form of playbooks to automate complex Kubernetes deployments and operations that would otherwise be out of reach to today’s DevOps teams.
How Keyva Can Help
The Keyva consulting team has focused skillsets in Ansible and OpenShift. Keyva is a Red Hat Apex partner, which is only awarded to a select group of top tier partners for services delivery in North America. The partnership gives our team access to latest technical information and training around Ansible and OpenShift.
We’re also an integration partner for Red Hat Ansible, having developed a ServiceNow module and other modules demonstrating our commitment to the platform and our ability to provide integration development capabilities besides professional services for the platform.
Our team has extensive experience in the domain of DevOps and Site Reliability Engineering (SRE). Our engineers can support clients with strategic initiatives, development and engineering, knowledge transfer, and mentoring. Using our Ansible and OpenShift experience, we can also help create third-party integrations to extend DevOps toolchains to meet your organization’s unique requirements.
[post_title] => Red Hat Ansible and OpenShift for DevOps - A Solution that Scales [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => the-power-of-red-hat-ansible-and-openshift-for-devops [to_ping] => [pinged] => [post_modified] => 2023-06-28 17:56:56 [post_modified_gmt] => 2023-06-28 17:56:56 [post_content_filtered] => [post_parent] => 0 [guid] => https://keyvatech.com/?p=3250 [menu_order] => 0 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [5] => WP_Post Object ( [ID] => 3246 [post_author] => 15 [post_date] => 2022-06-16 07:06:00 [post_date_gmt] => 2022-06-16 07:06:00 [post_content] =>Red Hat Ansible is a powerful configuration management tool available as open-source software and an enterprise version, Ansible Automation Platform. Enterprises can use Ansible as the technical foundation of an automated and scalable pipeline strategy that further standardizes how they deliver software to internal and external customers.
The Power of Red Hat Ansible
Any enterprise seeking an automation solution for their infrastructure or application deployments is an ideal user for Ansible. It's one of the most popular open-source software solutions on the market right now, and a de facto solution for standardized configuration management. Such popularity brings with it an active open-source community of contributors who are developing free modules and collections – integrations to third-party products such as networking, storage, and SaaS platforms. Ansible has thousands of modules, collections, and roles available for free via Ansible Galaxy.
The open-source and enterprise versions of Ansible are easy to use. Developers and engineers can write Ansible playbooks using YAML, a simple markup language that doesn't require any formal programming background. The primary use cases for Ansible are infrastructure automation for on-premise and cloud systems, and configuration management. Ansible provides Platform and Operations teams a common and standardized tool to be used across different workload types.
System Administrators can develop infrastructure automation using YAML playbooks. However, since Ansible is Python based, they can use a combination of Python and Shell scripting to easily customize the tool for their requirements, especially since System Administrators are typically familiar with both those scripting languages.
Ansible as Core to an Automation Strategy
Ansible can act as the foundation technology for an organization's automation strategy, starting with infrastructure automation such as provisioning workloads, patch management, and workload configuration management.
Organizations can use segments of their continuous integration/continuous development (CI/CD) pipelines and tie together their workstreams into a common platform. Ansible is easy to use, learn, and maintain, making it ideal to roll out to DevOps teams across a large enterprise to create standardization. Independent pockets of automation get formed in large organizations when one team is using Golang for scripting their automation tasks, another is using Python, and another team is using C#. When those programmers leave the company, their scripting knowledge leaves with them. Standardizing on Ansible helps with training and the documentation of common IT processes. Writing automation using YAML removes the dependency on knowing specific scripting languages and helps eliminate tech debt for such organizations.
Ansible Adoption and Scalability
Like many open source and DevOps tools, Ansible adoption is from the bottom up. For example, a developer or system administrator tries out and uses the community version in their environment to evaluate a fit. They may also have had success with it in the past or at another organization. Since it's free, easy to use, and open source, teams can start using it immediately for their automation requirements, and usage grows and proliferates across teams inside the organization.
Once the adoption of the open-source version of Ansible hits critical mass and teams get comfortable using it for automation widely across the organization, the next step would be to scale it for your organization. Red Hat’s Ansible Automation Platform is the enterprise-level solution which enables you to create high availability clusters in a supported confirmation. There are also other additional features - a GUI to create and manage job templates, schedule playbooks to run at a specific time, and triggering playbooks managed through git, IAM mappings, and more - which are not available with the open-source version.
Scaling Ansible to the Ansible Automation Platform means engaging with Red Hat to purchase licensing and support for the product. Red Hat also provides best practices for using the enterprise features.
A Keyva engagement starts during the architecture design phase, where the team will develop Ansible roles that support code reuse. The Keyva team would typically help our clients by design and develop an automation framework and building Ansible-based pipelines that can leverage existing modules and collections for reusability. The team also would develop playbooks – automation units within Ansible – and work with the customer to make them scalable and easy to support in-house.
As adoption grows, and the organization decides to use Ansible on thousands of nodes and target machines, Keyva and Red Hat can help build out processes and playbooks which effectively produce outcomes per your business requirements. Scalability and security are key facets to standing up solutions at an enterprise scale, and our combined expertise in building large scale environments is the core value-add we provide to our clients.
Every customer has their own inflection point for moving from the open-source Ansible to the Ansible Automation Platform. It's essential to acknowledge your scalability requirements with your internal teams and partners to find the right fit for your organization.
Ansible and Collaboration
Ansible enables DevOps teams to break down some of the traditional silos that are in every technology delivery organization. Multiple development and operations teams across business units can use Ansible as their standard platform for improving efficiency and achieving operational excellence.
The fact that Ansible uses YAML-based playbooks across the board means a standard environment for your DevOps teams that doesn't require skilling up team members. Team members across an organization can make recommendations or changes to infrastructure team playbooks for the benefit of all teams, not just their own.
Ansible is also flexible enough to fit into the latest DevOps processes or frameworks and legacy waterfall methodologies because the simplicity of YAML enables it to be plug and play. You have options to integrate Ansible with agile frameworks and tools such as Atlassian Jira and Azure DevOps. Engineers can work on tickets while following the workflows and processes set by Ansible playbooks because of pre-built integrations.
IT business leaders who are concerned with metrics also benefit from Ansible automation, because it enables faster resolution of incident tickets by their teams. Mean Time to Repair (MTTR) is a critical metric in operations organizations across industry verticals.
Ansible is also becoming a major component of AIOps because it helps enable self-healing infrastructure. If and when something goes wrong, Ansible playbooks can powers the automation and workflows to remediate the issues.
[post_title] => RedHat Ansible and the Power of Configuration Management [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => redhat-ansible-and-the-power-of-configuration-management [to_ping] => [pinged] => [post_modified] => 2023-06-28 17:57:11 [post_modified_gmt] => 2023-06-28 17:57:11 [post_content_filtered] => [post_parent] => 0 [guid] => https://keyvatech.com/?p=3246 [menu_order] => 0 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [6] => WP_Post Object ( [ID] => 3227 [post_author] => 15 [post_date] => 2022-06-06 13:18:36 [post_date_gmt] => 2022-06-06 13:18:36 [post_content] =>By Melveta Aitkinson - DevOps Engineer
This blog covers how to set up Flux for Helm and EKS.
First, let's cover what Flux, Helm, and EKS are. An important concept here is GitOps because Flux is a tool for GitOps. By definition, GitOps is an operational framework that takes DevOps best practices used for application development such as version control, collaboration, compliance, and CI/CD, and applies them to infrastructure automation. Flux allows you to synchronize the state of manifests (YAML files) in a Git repository to what is running in a cluster. So, what does this allow you to do? It allows for the direction of push code into different environments (Dev, QA, Prod) from the version-controlled system like Git and have it automatically updated in your Kubernetes cluster. This example illustrates the use of EKS in AWS. Let’s quickly touch on Helm. Think of Helm like a package manager. It helps install and manage Kubernetes applications, which is in the form of Helm charts.
Requirements:
GIT
Helm
Flux
Git/Helm repository (in this example we will be using GitLab)
A running Kubernetes cluster and kubectl (in this example we will be using EKS in AWS)
Environment setup:
If you are following this example using EKS, please feel free to use https://keyvatech.com/2022/02/25/create-eks-clusters-in-aws-using-eksctl/ to quickly spin up a EKS cluster. Remember to shut down unused resources. This is for commands running on a Mac, some steps may differ on another OS:
LINKEDIN Environment setup:
If you are following this example using EKS, https://docs.aws.amazon.com/eks/latest/userguide/getting-started.html. Remember to shut down unused resources. This is for commands running on a Mac, some steps may differ on another OS:
Setting up Flux
- Creating a Helm Chart
helm create <chartname>Bootstrap Kubernetes cluster
- This installs Flux on Kubernetes cluster
- If namespace is not included, Flux will create/use a default namespace of “Flux-system”
flux bootstrap gitlab --ssh-hostname=gitlab.com --owner=<group owner of repository> --repository=<name of repository> --path=<directoy path to be synced> --branch=<repository branch> --namespace <kubernetes namespace>Add Helm repository
- Adds GitLab repository as Helm chart repository, allowing for a centralized location to store Helm charts
helm repo add --username <gitlab username> --password <gitlab token> <repository name> <https://gitlab.com/api/v4/projects/><project id>/packages/helm/stablePackage Helm chart
- chartname is the same as the create chart command
- Command produces a file with the following format: <chartname>-0.1.0.tgz in the directory that command is executed
helm **package** <chartname>Push Helm chart
- Helm repo is the same used in the Helm repo add command
helm cm-push <chartname>-0.1.0.tgz <helm repo>Create a Helm source
- Creates a Helm repo from the URL provided and fetches an index
flux create source helm <name of source> --url=https://gitlab.com/api/v4/projects/<project_id>/packages/helm/stable --interval=<interval for sync> --username=<gitlab username> --password=<gitlab token> --namespace <kubernetes namespace>Create a Helm release
- Pulls down the chart, deploys resources and syncs with the cluster
flux create helmrelease <name of helmrelease> --chart=<chartname> --source=HelmRepository/<repo name> --chart-version="<chart-version>" --namespace <kubernetes namespace>Confirm Helm release and charts with the following commands:
kubectl get hr -A
helm list -A
By: Saikrishna Madupu - Sr Devops Engineer
Deploying Kubernetes using KinD can help setup a test environment where you can build multi-nodes or multiple clusters.
If you want to create clusters on virtual machines, you should have the resources to run the virtual machines. Each machine should have adequate disk space, memory, and CPU utilization. An alternate way to overcome this high volume of resources is to use containers in place. Using containers provides the advantage to run additional nodes, as per the requirements, by creating/deleting them in minutes and helps run multiple clusters on a single host. To explain how to run a cluster using only containers locally, use Kubernetes in Docker (KinD) to create a Kubernetes cluster on your Docker host.
Why pick KIND for test env’s[KH1] ?
- KinD can create a new multi-node cluster in minutes
- Separate the control plane and worker nodes to provide a more "realistic" cluster
- In order to limit the hardware requirements and to make Ingress easier to configure, only create a two-node cluster
- A multi-node cluster can be created in a few minutes and once testing has been completed, clusters can be torn down in a few seconds
Pre-requisites:
- Docker daemon to create a cluster
- It supports most of the platforms below
- Linux
- macOS running Docker Desktop
- Windows running Docker Desktop
- Windows running WSL2
How kind works:
At a high level, you can think of a KinD cluster as consisting of a single Docker container that runs a control plane node and a worker node to create a Kubernetes cluster. To make the deployment easy and robust, KinD bundles every Kubernetes object into a single image, known as a node image. This node image contains all the required Kubernetes components to create a single-node or multi-node cluster. Once it is up and running, you can use Docker to exec into a control plane node container. It comes with the standard k8 components and comes with default CNI [KINDNET]. We can also disable default CNI and enable such as Calico, Falnnel, Cilium. Since KinD uses Docker as the container engine to run the cluster nodes, all clusters are limited to the same network constraints that a standard Docker container is limited to. We can also run other containers on our kind env by passing an extra argument –net=kind to the docker run command.
KinD Installation:
I’m using Mac for demonstration and will also point out the steps to install it manually.
Option1:
brew install kind
Option2:
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.11.1/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/bin
You can verify the installation of kind by simply running:
kind version kind v0.11.1 go1.16.4 darwin/arm64
- KinD create cluster this will create a new k8 cluster with all components in a single docker container named by kind as shown below:
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.21.1) ?
✓ Preparing nodes ?
✓ Writing configuration ?
✓ Starting control-plane ?️
✓ Installing CNI ?
✓ Installing StorageClass ?
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a nice day! ?
- As part of this cluster creation, it also modifies/creates config file which is used to access the cluster
- We can verify the newly built cluster by running kubectl get nodes
NAME STATUS ROLES AGE VERSION kind-control-plane Ready control-plane,master 5m54s v1.21.1
KinD helps us to create and delete the cluster very quick. In order to delete the cluster we use KinD delete cluster in this example, it also deletes entry in our ~/.kube/config file that gets appended when cluster gets created.
kind delete cluster --name <cluster name>
Creating a multi-node cluster:
When creating a multi-node cluster, with custom options we need to create a cluster config file. Setting values in this file allows you to customize the KinD cluster, including the number of nodes, API options, and more. Sample config is shown below:
Config file:
/Cluster01-kind.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
apiServerAddress: "0.0.0.0"
disableDefaultCNI: true
apiServerPort: 6443
kubeadmConfigPatches:
- |
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
metadata:
name: config
networking:
serviceSubnet: "10.96.0.1/12"
podSubnet: "10.240.0.0/16"
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 2379
hostPort: 2379
extraMounts:
- hostPath: /dev
containerPath: /dev
- hostPath: /var/run/docker.sock
containerPath: /var/run/docker.sock
- role: worker
extraPortMappings:
- containerPort: 80
hostPort: 80
- containerPort: 443
hostPort: 443
- containerPort: 2222
hostPort: 2222
extraMounts:
- hostPath: /dev
containerPath: /dev
- hostPath: /var/run/docker.sock
containerPath: /var/run/docker.sock
apiserverAddress:
What IP address the API server will listen on. By default it will use 127.0.0.1, but since we plan to use the cluster from other networked machines, we have selected to listen on all IP addresses.
disableefaultCNI: Enable or disable the Kindnet installation. The default value is false.
kubeadmConfigPatches:
This section allows you to set values for other cluster options during the installation. For our configuration, we are setting the CIDR ranges for the ServiceSubnet and the podSubnet.
Nodes:
For our cluster, we will create a single control plane node, and a single worker node.
role:control-plane:
The first role section is for the control-plane. We have added options to map the localhosts/dev and /var/run/Docker. Sock, which will be used in the Falco chapter, later in the book.
role:worker:
This is the second node section, which allows you to configure options that the worker nodes will use. For our cluster, we have added the same local mounts that will be used for Falco, and we have also added additional ports to expose for our Ingress controller.
ExportPortMapping:
To expose ports to your KinD nodes, you need to add them to the extraPortMappings section of the configuration. Each mapping has two values, the container port, and the host port. The host port is the port you would use to target the cluster, while the container port is the port that the container is listening on.
Extramounts:
The extra Mounts section allows you to add extra mount points to the containers. This comes in handy to expose mounts like /dev and /var/run/Docker. Sock that we will need for the Falco chapter.
Multi-node cluster configuration:
kind: Cluster apiVersion: kind.x-k8s.io/v1alpha4 nodes: - role: control-plane - role: control-plane - role: control-plane - role: worker - role: worker - role: worker kind create cluster --name cluster01 --config cluster-01.yaml
Set kubectl context to "kind-multinode"
You can now use your cluster with:
kubectl cluster-info --context kind-multinode Note: The –name option will set the name of the cluster to cluster-01, and –config tells the installer to use the cluster01-kind.yaml config file.
Multiple control plane servers introduce additional complexity since we can only target a single host or IP in our configuration files. To make this configuration usable, we need to deploy a load balancer in front of our cluster. If you do deploy multiple control plane nodes, the installation will create an additional container running a HAProxy load balancer.
- Creating cluster "multinode" ...
- Ensuring node image (kindest/node:v1.21.1)
- Preparing nodes
- Configuring the external load balancer
- Writing configuration
- Starting control-plane
- Installing StorageClass
- Joining more control-plane nodes
- Joining worker nodes
Have a question, bug, or feature request? Let us know! https:
Since we have a single host, each control plane node and the HAProxy container are running on unique ports. Each container needs to be exposed to the host so that they can receive incoming requests. In this example, the important one to note is the port assigned to HAProxy, since that's the target port for the cluster. In Kubernetes config file, we can see that it is targeting https://127.0.0.1:42673, which is the port that's been allocated to the HAProxy container.
When a command is executed using kubectl, it directs to the HAProxy server. Using a configuration file that was created by KinD during the cluster's creation, with the help of HA Proxy traffic gets routed between the three control plane nodes. In the HAProxy container, we can verify the configuration by viewing the config file, found at /usr/local/etc/haproxy/haproxy.cfg:
# generated by kind
global log /dev/log local0 log /dev/log local1 notice daemon resolvers docker nameserver dns 127.0.0.11:53 defaults log global mode tcp option dontlognull # TODO: tune these timeout connect 5000 timeout client 50000 timeout server 50000 # allow to boot despite dns don't resolve backends default-server init-addr none frontend control-plane bind *:6443 default_backend kube-apiservers backend kube-apiservers option httpchk GET /healthz # TODO: we should be verifying (!) server multinode-control-plane multinode-control-plane:6443 check check-ssl verify none resolvers docker resolve-prefer ipv4 server multinode-control-plane2 multinode-control-plane2:6443 check check-ssl verify none resolvers docker resolve-prefer ipv4 server multinode-control-plane3 multinode-control-plane3:6443 check check-ssl verify no resolvers docker resolve-prefer ipv4
As shown in the preceding configuration file, there is a backend section called kube-apiservers that contains the three control plane containers. Each entry contains the Docker IP address of a control plane node with a port assignment of 6443, targeting the API server running in the container. When you request https://127.0.0.1:32791, that request will hit the HAProxy container, then, using the rules in the HAProxy configuration file, the request will be routed to one of the three nodes in the list.
Since our cluster is now fronted by a load balancer, you have a highly available control plane for testing.
[post_title] => Deploy Kubernetes using KinD [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => deploy-kubernetes-using-kind [to_ping] => [pinged] => [post_modified] => 2023-06-28 17:57:30 [post_modified_gmt] => 2023-06-28 17:57:30 [post_content_filtered] => [post_parent] => 0 [guid] => https://keyvatech.com/?p=3218 [menu_order] => 0 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) ) [post_count] => 8 [current_post] => -1 [before_loop] => 1 [in_the_loop] => [post] => WP_Post Object ( [ID] => 3335 [post_author] => 7 [post_date] => 2022-08-23 18:54:15 [post_date_gmt] => 2022-08-23 18:54:15 [post_content] =>By: Saikrishna Madupu – Sr Devops Engineer
In this blog, we will cover what is Goss, and how to leverage it for automated server validation testing.
What is Goss:
Goss is a YAML based serverspec alternative tool for validating a server’s configuration. It eases the process of writing tests by allowing the user to generate tests from the current system state. Once the test suite is written they can be executed, waited-on, or served as a health endpoint. You can do server validation quickly and easily with Goss and integrate with pipelines to monitor the status of any services.
I’ll be using airflow for a target test case. First, we will install airflow locally and validate the status of airflow service status using Goss.
https://github.com/aelsabbahy/goss
Goss Installation:
- OPTION 1:
curl -L https://github.com/aelsabbahy/goss/releases/download/v0.3.7/goss-linux-amd64 -o /usr/local/bin/goss
curl -L https://raw.githubusercontent.com/aelsabbahy/goss/master/extras/dgoss/dgoss -o /usr/local/bin/dgoss
chmod +rx /usr/local/bin/dgoss- OPTION 2:
https://ports.macports.org/port/goss/
Install Macports and run
sudo port install goss
## Add the following line to your ~/.profile or .zshrc
export GOSS_PATH=/usr/local/bin/goss
Use Case:
We will deploy Apache Airflow locally and validate the status of webserver using Goss. Airflow is an open-source project used to programmatically author, schedule, and monitor workflows. You can find more about airflow here - https://airflow.apache.org/
export AIRFLOW_HOME=~/airflow
pip3 install apache-airflow
pip3 install typing_extensions
# initialize the database
airflow initdb
# start the web server, default port is 8080
airflow webserver -p 8080
# start the scheduler. I recommend opening up a separate terminal \
# window for this step
airflow scheduler
# open localhost:8080 in the browser and enable the example dag via the home pageValidation:
Goss.yaml file validates HTTP response status code and content
export GOSS_USE_ALPHA=1
goss validate goss.yaml
- As the webserver is not up and running we see the error above
After starting the airflow webserver and making sure the application is up and running by validating it (via opening the page in a browser)
- goss validate goss.yaml would return the status report as shown below.
- Goss also supports several other test cases. Some of those are listed below:
- Addr
- Command
- Dns
- Ount
- Package
- Service
Ref: https://github.com/aelsabbahy/goss/blob/master/docs/manual.md#goss-test-creation
About the Author
[table id =5 /]
[post_title] => GOSS Server Validation [post_excerpt] => [post_status] => publish [comment_status] => closed [ping_status] => closed [post_password] => [post_name] => goss-server-validation [to_ping] => [pinged] => [post_modified] => 2022-08-23 22:00:44 [post_modified_gmt] => 2022-08-23 22:00:44 [post_content_filtered] => [post_parent] => 0 [guid] => https://keyvatech.com/?p=3335 [menu_order] => 0 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [comment_count] => 0 [current_comment] => -1 [found_posts] => 162 [max_num_pages] => 21 [max_num_comment_pages] => 0 [is_single] => [is_preview] => [is_page] => [is_archive] => [is_date] => [is_year] => [is_month] => [is_day] => [is_time] => [is_author] => [is_category] => [is_tag] => [is_tax] => [is_search] => [is_feed] => [is_comment_feed] => [is_trackback] => [is_home] => 1 [is_privacy_policy] => [is_404] => [is_embed] => [is_paged] => 1 [is_admin] => [is_attachment] => [is_singular] => [is_robots] => [is_favicon] => [is_posts_page] => [is_post_type_archive] => [query_vars_hash:WP_Query:private] => 2f81d7721674a56fe84c555fe214246a [query_vars_changed:WP_Query:private] => [thumbnails_cached] => [allow_query_attachment_by_filename:protected] => [stopwords:WP_Query:private] => [compat_fields:WP_Query:private] => Array ( [0] => query_vars_hash [1] => query_vars_changed ) [compat_methods:WP_Query:private] => Array ( [0] => init_query_flags [1] => parse_tax_query ) [query_cache_key:WP_Query:private] => wp_query:8851f344e40b221c860a61e5d02542ba [tribe_is_event] => [tribe_is_multi_posttype] => [tribe_is_event_category] => [tribe_is_event_venue] => [tribe_is_event_organizer] => [tribe_is_event_query] => [tribe_is_past] => )
GOSS Server Validation

ServiceNow App for Red Hat Ansible – Certified for San Diego Release

How to Apply Kyverno Policies for Your Kubernetes Cluster

ServiceNow App for Red Hat OpenShift – Certified for San Diego Release

Red Hat Ansible and OpenShift for DevOps – A Solution that Scales

RedHat Ansible and the Power of Configuration Management

GitOps – Flux / Helm
