
In this blog post, we will explore how Terraform can be utilized to create a BigQuery database in Google Cloud (GCP). BigQuery is one of the most popular GCP services due to its many advantages. BigQuery is a fully managed petabyte scale data warehouse database that uses SQL. Its serverless and allows you to query external data sources without having to store that data inside GCP itself. An important note is that a major advantage of BigQuery is that you pay for the data scanned and not the amount of data stored.
Terraform
GCP Account
Environment setup:
Before you begin, make sure you have a valid Google Cloud account and project setup. We are also going to use a service account to generate the database via Google recommended best practices. Also, make sure you have Terraform installed on your local machine. Terraform provides official documentation on how to do this.
Create a new directory in the desired location and navigate to it and paste the following code to create the BigQuery database:
#Setup RHEL subscription
subscription-manager register
provider "google" {
credentials = file("<service_account_key_file>.json")
project = "<ID of your GCP project>"
region = "us-central1"
zone = "us-central1-a"
}
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "4.51.0"
}
}
}
resource "google_bigquery_dataset" "bigquery_blog" {
dataset_id = "bigquery_blog"
friendly_name = "blog"
description = "Dataset for blog"
location = "US"
labels = {
env = "dev"
}
}
resource "google_bigquery_table" "bigquery_blog" {
dataset_id = google_bigquery_dataset.bigquery_blog.dataset_id
table_id = "blogs"
time_partitioning {
type = "DAY"
}
labels = {
env = "dev"
}
schema = <<EOF
[
{
"name": "blog_title",
"type": "STRING",
"mode": "NULLABLE",
"description": "Name of blog"
},
{
"name": "blog_date",
"type": "DATETIME",
"mode": "NULLABLE",
"description": "Date of blog"
}
]
EOF
}
Now let’s break down the above code:
The provider block uses the Google provider which is a plugin that is used for resources management. Here we define the service account credentials file that we want to use create the database also the project ID, region and zone. For the service account, we use least privilege access and just scope its permissions to BigQuery.
Next, we have the resource blocks. Before we create the actual table, we need to create a dataset. A BigQuery dataset is thought of as a container for tables. You can house multiple tables in a dataset or just have a single table. Here we set the location to “US” and add labels so that we can easily id the table. For the table resource, I would like to point out we added a time partitioning configuration. It is recommended that you partition tables and data because it helps with maintainability and query performance.
Creating the database:
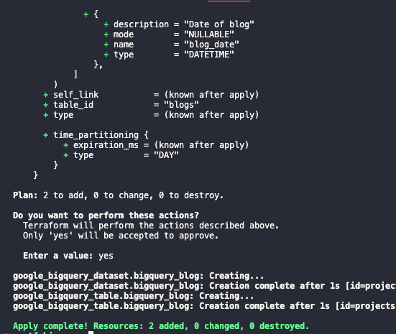
Then we will run the following commands to create the database in GCP with our service account.
terraform init
terraform plan
terraform apply
After running apply, you should see a similar output with the success of the terraform apply.
About the Author
[table “7” not found /]